Scrape data from web pages
️✅ Learning objectives
- Decide whether to scrape data from a web page.
- Use {polite} to responsibly scrape web pages.
- Scrape complex data structures from web pages.
- Scrape content that requires interaction.
Decide whether to scrape data
Do I need to scrape this data?
- Look for an API!
- Try {datapasta} 📦
- RStudio Addins
- If it’s one time & over-complicated, consider other copy/paste strategies
- Only scrape pages you need
Can I legally scrape this data?
- ⚠️ Legal disclaimers (but may be over-protective)
- USA:
- Can’t copyright facts,
- CAN copyright collections of facts in some cases (creative)
- TidyTuesday 2023-08-29: Fair Use
- Other places:
- Sometimes stricter (EU)
- Sometimes more lax
- ✅ Personal use or nonprofit education usually ok
- ⚠️ Personally Identifiable Information (PII)
Should I scrape this data?
User-agent: *= everybody- Search for name(s) of package(s)
- Search for specific pages within site
- Check root of site (
/) and your particular subfolder - These aren’t (necessarily) legally binding
- {robotstxt} 📦 for parsing
robots.txt - {polite} 📦 wraps and applies {robotstxt}
Scrape non-tabular data
Motivating example: Cheese
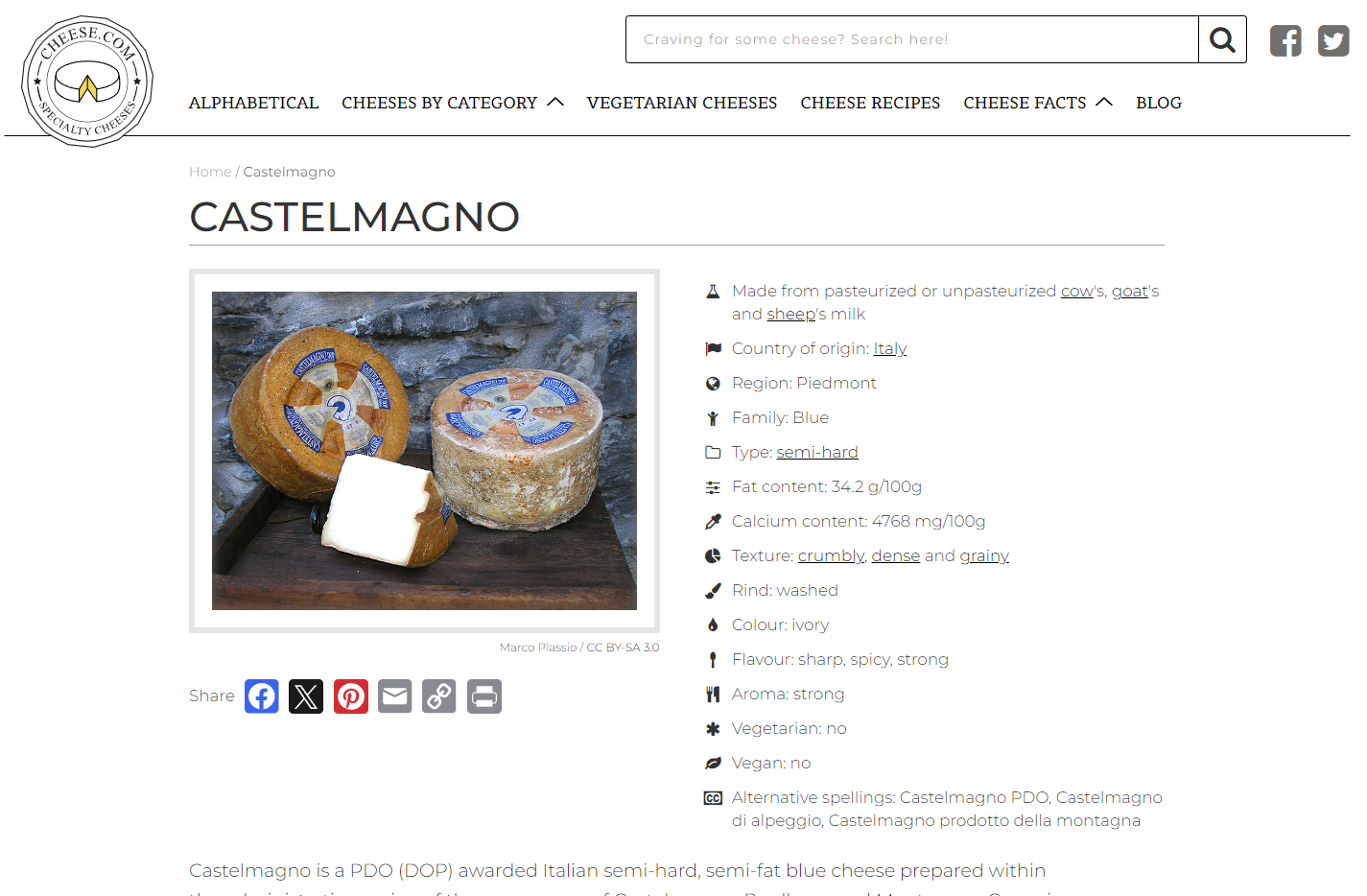
Three steps of web scraping with {rvest}
See R4DS Chapter 24: “Web Scraping” for a full introduction
- Load the page.
- Find the object(s) (observations & variables) you want.
- Extract variables (text) into R object(s).
Use {polite} to scrape respectfully
Load the page: bow() + scrape()
session <- polite::bow(
"https://www.cheese.com/castelmagno/",
user_agent = "rvest/1.0.4 (Jon Harmon; mailto:jonthegeek+useragent@gmail.com)",
delay = 0,
verbose = TRUE
)
session
#> <polite session> https://www.cheese.com/castelmagno/
#> User-agent: rvest/1.0.4 (Jon Harmon; https://wapir.io; mailto:jonthegeek+useragent@gmail.com)
#> robots.txt: 0 rules are defined for 1 bots
#> Crawl delay: 0 sec
#> The path is scrapable for this user-agentFind the object(s)
https://www.cheese.com/castelmagno
- Select a specific element from R4DS slides
Selected elements
- html_element() vs html_elements() from R4DS slides
summary_points <- castelmagno_page |>
rvest::html_elements(".summary-points li")
summary_points
#> {xml_nodeset (15)}
#> [1] <li class="summary_milk">\n ...
#> [2] <li class="summary_country">\n ...
#> [3] <li class="summary_region">\n ...
#> [4] <li class="summary_family">\n ...
#> [5] <li class="summary_moisture_and_type">\n ...
#> [6] <li class="summary_fat">\n ...
#> [7] <li class="summary_calcium">\n ...
#> [8] <li class="summary_texture">\n ...
#> [9] <li class="summary_rind">\n ...
#> [10] <li class="summary_tint">\n ...
#> [11] <li class="summary_taste">\n ...
#> [12] <li class="summary_smell">\n ...
#> [13] <li class="summary_vegetarian">\n ...
#> [14] <li class="summary_vegan">\n ...
#> [15] <li class="summary_alt_spelling">\n ...Extract variables
cheese_data <- tibble::tibble(!!!cheese_variables)
#> $ milk <chr> "Made from pasteurized or unpasteurized cow's, goat's and sheep's milk"
#> $ country <chr> "Italy"
#> $ region <chr> "Piedmont"
#> $ family <chr> "Blue"
#> $ moisture_and_type <chr> "semi-hard"
#> $ fat <chr> "34.2 g/100g"
#> $ calcium <chr> "4768 mg/100g"
#> $ texture <chr> "crumbly, dense and grainy"
#> $ rind <chr> "washed"
#> $ tint <chr> "ivory"
#> $ taste <chr> "sharp, spicy, strong"
#> $ smell <chr> "strong"
#> $ vegetarian <chr> "no"
#> $ vegan <chr> "no"
#> $ alt_spelling <chr> "Castelmagno PDO, Castelmagno di alpeggio, Castelmagno prodotto della montagna"Aside: Cleaning
cheese_data |>
dplyr::mutate(
vegetarian = vegetarian == "yes",
vegan = vegan == "yes",
dplyr::across(
c("fat", "calcium"),
\(x) as.double(stringr::str_remove(x, " m?g/100g"))
),
dplyr::across(
c(-"milk", -"vegetarian", -"vegan", -"fat", -"calcium"),
\(x) stringr::str_split(x, "(, )|( and )")
)
) |>
dplyr::mutate(
pasteurized = stringr::str_detect(milk, "\\bpasteurized"),
unpasteurized = stringr::str_detect(milk, "\\bunpasteurized"),
animal = stringr::str_extract_all(milk, "(\\S+)(?='s)"),
.before = "milk",
.keep = "unused"
) |>
dplyr::glimpse()
#> Rows: 1
#> Columns: 17
#> $ pasteurized <lgl> TRUE
#> $ unpasteurized <lgl> TRUE
#> $ animal <list> <"cow", "goat", "sheep">
#> $ country <list> "Italy"
#> $ region <list> "Piedmont"
#> $ family <list> "Blue"
#> $ moisture_and_type <list> "semi-hard"
#> $ fat <dbl> 34.2
#> $ calcium <dbl> 4768
#> $ texture <list> <"crumbly", "dense", "grainy">
#> $ rind <list> "washed"
#> $ tint <list> "ivory"
#> $ taste <list> <"sharp", "spicy", "strong">
#> $ smell <list> "strong"
#> $ vegetarian <lgl> FALSE
#> $ vegan <lgl> FALSE
#> $ alt_spelling <list> <"Castelmagno PDO", "Castelmagno di alpeggio", "Castelmagno prodotto della montagna"…Scrape interactive web pages
read_html_live
- Data: HMdb.org
- Live-coding!
session <- rvest::read_html_live("https://www.hmdb.org/geolists.asp")
session |>
rvest::html_element("#StatesList") |>
rvest::html_text2()
session |>
rvest::html_element("div.bodysansserif") |>
rvest::html_elements("td:nth-child(2)") |>
rvest::html_text2()
session$click("tr:nth-child(1) .countryarrow")
session |>
rvest::html_element("#StatesList") |>
rvest::html_text2()
session$click("tr:nth-child(2) .countryarrow")
session |>
rvest::html_element("#StatesList") |>
rvest::html_text2()
session |>
rvest::html_element("#StateSidebar") |>
rvest::html_elements("td:nth-child(2)") |>
rvest::html_text2()
session |>
rvest::html_element("#CountiesList") |>
rvest::html_text2()
session$click("#StateSidebar tr:nth-child(3) .statearrow")
session |>
rvest::html_element("#CountiesList") |>
rvest::html_text2()
session |>
rvest::html_element("#CountySidebar") |>
rvest::html_elements("a") |>
rvest::html_text2()
session |>
rvest::html_element("#CountySidebar") |>
rvest::html_elements("a") |>
rvest::html_attr("href")Chapter To-Do
DSLC.io/wapir | Jon Harmon | wapir.io